Keyword [Facial Action Units]
Zhao K, Chu W S, Zhang H. Deep region and multi-label learning for facial action unit detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 3391-3399.
1. Overview
在人脸AU检测中,存在两种常见的任务
- Region Learning (RL)
- Multi-label Learning (ML)
论文将两者进行结合,提出能够同时解决上述两个任务的框架Deep Region and Multi-label Learning (DRML)。

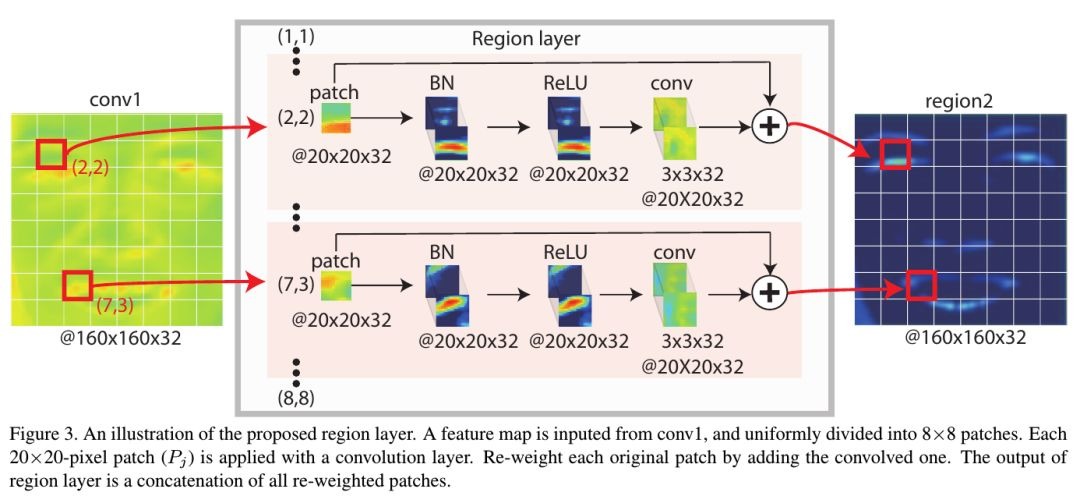
框架中包含一个region laryer结构。 region layer可通过两种方式设计
- locally connected layers (LCN). 每个像素点对应一个卷积核(参数量较大)
- conventional convolution layers. 首先将输入特征图分成n*m个region, 每个region内的像素点共享卷积核权重(即每个region通过一个卷积层)
DRML框架特点
- end to end训练
- non-linear模型
论文在BP4D和DISFA数据集上进行实验,对比F1-score和AUC评价指标。
1.1. Region Learning
- 通过传统方法识别特定的区域来提高检测性能(类似于Attention)。例如patch-based方法,首先将图像划分为patch,然后将patch分类为普通patch和特定patch来描述不同的表情
- patch-based 缺点. easily fail on faces with modest or large pose (某些patch中部分相关,但被排除在外,没有用于识别,从而导致性能降低)
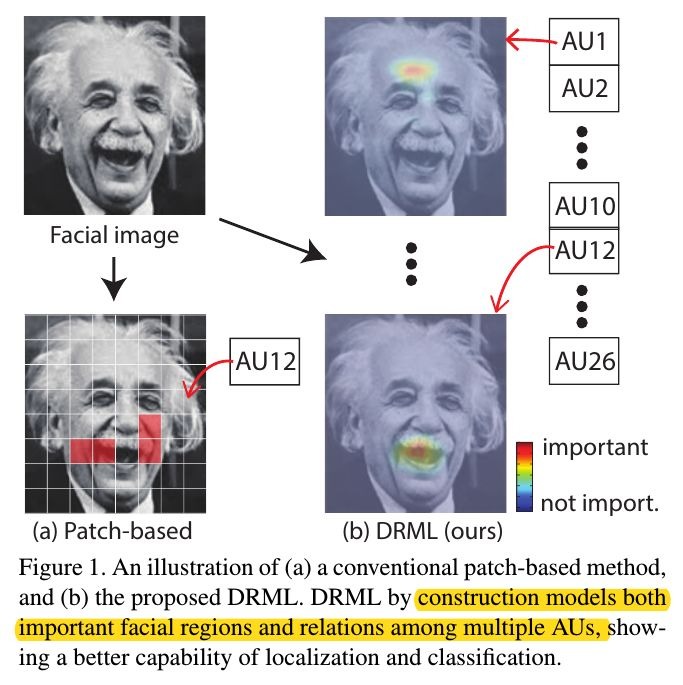
1.2. Multi-label Learning
- 传统的AU检测方法(AdaBoost、SVM等)都是对某个AU进行检测
- ML对于每个表情,同时预测多个AU。 能够在一定程度上解决正负样本不平衡的问题
1.3. 评价指标
- F1-score. precision和recall的调和均值,常用于AU检测
- AUC. 量化true positive和false positive之间的关系
2. DRML结构
大多数表情分析都使用很小的人脸图像(如4848)作为输入,为了避免人脸微小细节的丢失,论文使用**170170**大小的图像作为输入。
2.1. Loss Function

2.2. Region Layer
- 人脸图像相对于自然图像更加结构化,不同的人脸区域具有不同的局部统计。因此,可使用LCN(参数太多)或者区域卷积进行处理
- 可看做是对每个区域进行Attention操作
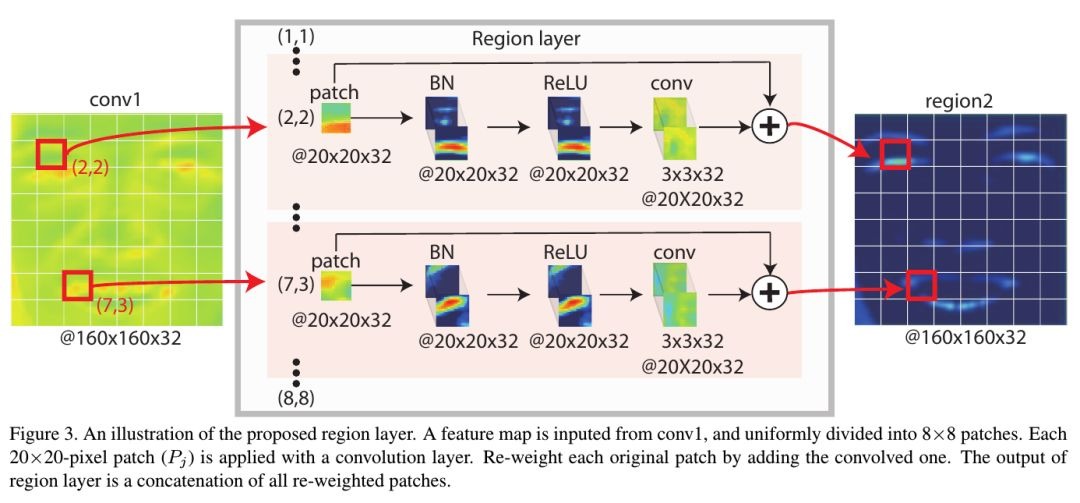
结构包含三部分
- patch clipping (论文采用8*8 grid)
- local convolution
- identity addition (避免梯度消失;如果patch与AU检测无关,it would be easier to directly forward the patch than learning a filter bank to reduce the patch’s effect)
2.3. Region可视化
使用saliency map(通过计算每个像素点对于某个特定AU的梯度级数)进行可视化。
2.4. 与相关工作的比较
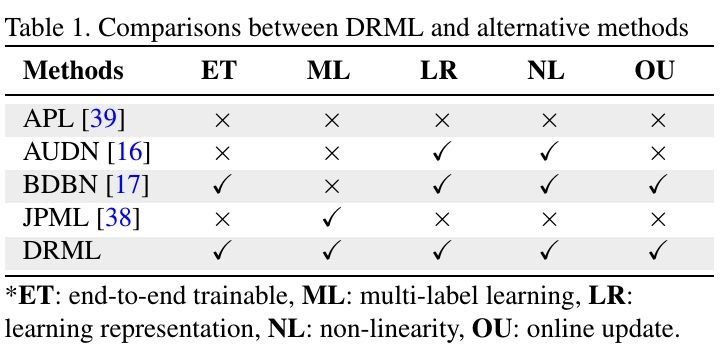
DRML受JPML启发,但存在不同之处
- JPML通过对数据集统计,定义AU关系
- JPML使用manually-crafted feature (SIFT)
- JPML轮流学习PL和ML
- JPML线性
3. Experiments
200200图像random crop为170170,并进行horizontally mirrored。
DRML收敛更快,训练loss更低,更接近gt统计
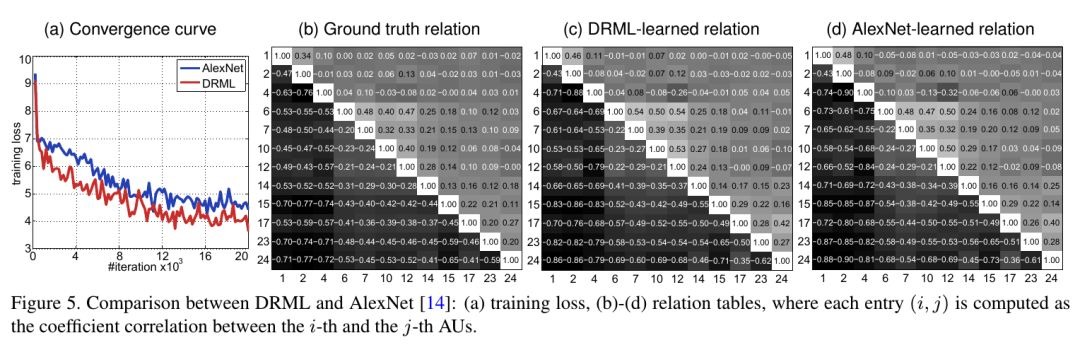
DRML比LCN速度快;ConvNet(去掉Region Layer的DRML)比AlexNet速度慢(由于卷积核为11*11)

3.1. BP4D&DISFA实验结果
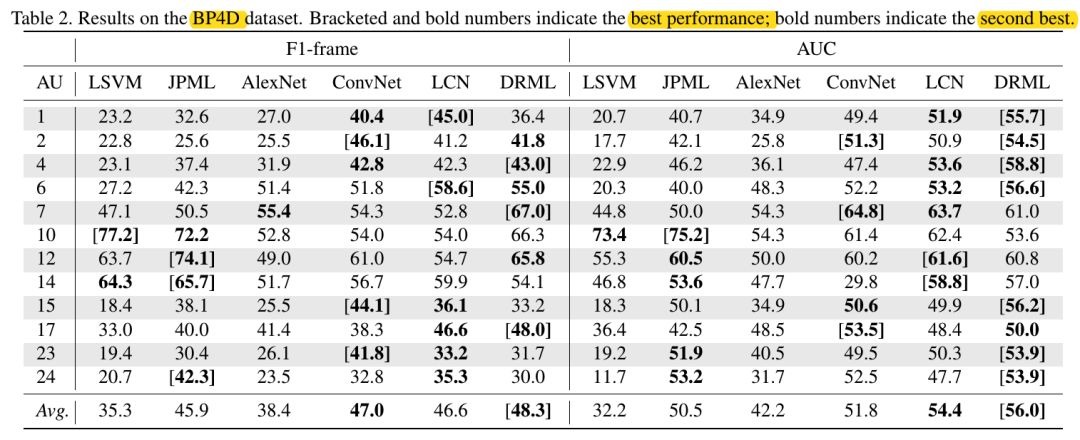
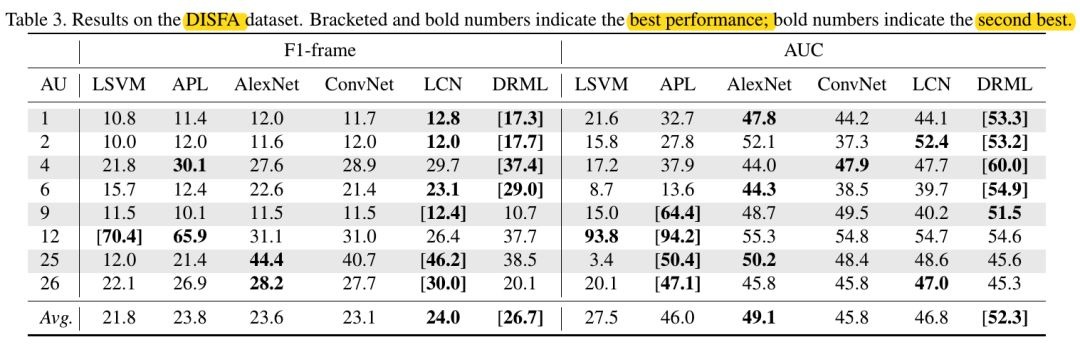
- learned features are of lower dimension, more than 40% of learned features for AlexNet, LCN, and DRML, are zeros
- Multi-label训练提高了效果
- 当训练数据很少时,multi-label学习能够减少imbalance的影响